自考题库
首页
所有科目
自考历年真题
考试分类
关于本站
游客
账号设置
退出登录
注册
登录
出自:数据挖掘工程师
怎样从历史数据中训练出结点之间的条件概率或联合条件概率?
简述缺失值的处理方法。
许多基于内存的聚类算法所常用的两种数据结构是()和()
什么是关联规则?关联规则的应用有哪些?
通过聚集多个分类器的预测来提高分类准确率的技术称为()。
A:组合(ensemble)
B:聚集(aggregate)
C:合并(combination)
D:投票(voting)
连续型属性的数据样本之间的距离有欧氏距离、曼哈顿距离和()
使用星型模式可以从一定程度上()查询效率。因为星型模式中数据的组织已经经过预处理,主要数据都在庞大的事实表中。
OLAP服务器的类型主要包括:()、()和()
根据特征选择过程与后续 数据挖掘任务的关联可分为三种方法:()。根据是否用到类信息的指导,分为(),()和()特征选择,
数据仓库就是一个面向主题的、集成的、()、反映历史变化的数据集合。
方体计算的主要挑战是()和()之间的矛盾。
以下哪种聚类方法可以发现任意形状的聚类?()
A:划分的方法
B:基于模型的方法
C:基于密度的方法
D:层次的方法
什么是分类?分类的应用领域有哪些?
()都属于分裂的层次聚类算法。
A:二分K均值
B:MST
C:Chameleon
D:组平均
为什么要进行维归约?
比较OLAP的数据模型MOLAP与ROLAP?
考虑下表数据集,请完成以下问题:
(1)估计条件概率
。 (2)根据(1)中的条件概率,使用朴素贝叶斯方法预测测试样本(A=0,B=1,C=0)的类标号; (3)使用Laplace估计方法,其中p=1/2,l=4,估计条件概率
。 (4)同(2),使用(3)中的条件概率。 (5)比较估计概率的两种方法,哪一种更好,为什么?
簇有效性的面向相似性的度量包括()。
A:精度
B:Rand统计量
C:Jaccard系数
D:召回率
数据库中的知识挖掘(KDD)包括以下七个步骤:()、()、()、()、()、()和()
假设属性income的最大最小值分别是12000元和98000元。利用最大最小规范化的方法将属性的值映射到0至1的范围内。对属性income的73600元将被转化为:()。
A:0.821
B:1.224
C:1.458
D:0.716
比较统计学与数据挖掘的异同?
什么是关于数据仓库映射的元数据?
如果对属性值的任一组合,R中都存在一条规则加以覆盖,则称规则集R中的规则为()。
A:无序规则
B:穷举规则
C:互斥规则
D:有序规则
数据仓库是随着时间变化的,下面的描述
不正确
的是()
A:数据仓库随时间的变化不断增加新的数据内容
B:捕捉到的新数据会覆盖原来的快照
C:数据仓库随事件变化不断删去旧的数据内容
D:数据仓库中包含大量的综合数据,这些综合数据会随着时间的变化不断地进行重新综合
下面关于数据粒度的描述
不正确
的是()
A:粒度是指数据仓库小数据单元的详细程度和级别
B:数据越详细,粒度就越小,级别也就越高
C:数据综合度越高,粒度也就越大,级别也就越高
D:粒度的具体划分将直接影响数据仓库中的数据量以及查询质量
在聚类分析当中,()等技术可以处理任意形状的簇。
A:MIN(单链)
B:MAX(全链)
C:组平均
D:Chameleon
数据离散度的常用度量包括()
简述联机分析处理的四个特征?
一个数据库有5个事务,如表所示。设min_sup=60%,min_conf=80%。
(a)分别用Apriori算法和FP-growth算法找出所有频繁项集。比较两种挖掘方法的效率。 (b)比较穷举法和Apriori算法生成的候选项集的数量。 (c)利用(1)所找出的频繁项集,生成所有的强关联规则和对应的支持度和置信度。
根据关联分析中所涉及的抽象层,可以将关联规则分类为()。
A:布尔关联规则
B:单层关联规则
C:多维关联规则
D:多层关联规则
首页
<上一页
3
4
5
6
7
下一页>
尾页
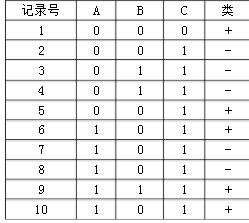 (1)估计条件概率
(1)估计条件概率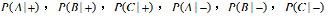 。 (2)根据(1)中的条件概率,使用朴素贝叶斯方法预测测试样本(A=0,B=1,C=0)的类标号; (3)使用Laplace估计方法,其中p=1/2,l=4,估计条件概率
。 (2)根据(1)中的条件概率,使用朴素贝叶斯方法预测测试样本(A=0,B=1,C=0)的类标号; (3)使用Laplace估计方法,其中p=1/2,l=4,估计条件概率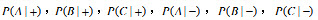 。 (4)同(2),使用(3)中的条件概率。 (5)比较估计概率的两种方法,哪一种更好,为什么?
。 (4)同(2),使用(3)中的条件概率。 (5)比较估计概率的两种方法,哪一种更好,为什么?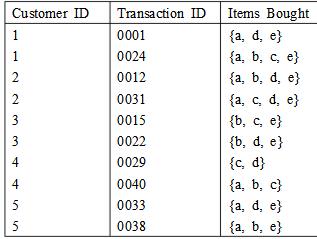 (a)分别用Apriori算法和FP-growth算法找出所有频繁项集。比较两种挖掘方法的效率。 (b)比较穷举法和Apriori算法生成的候选项集的数量。 (c)利用(1)所找出的频繁项集,生成所有的强关联规则和对应的支持度和置信度。
(a)分别用Apriori算法和FP-growth算法找出所有频繁项集。比较两种挖掘方法的效率。 (b)比较穷举法和Apriori算法生成的候选项集的数量。 (c)利用(1)所找出的频繁项集,生成所有的强关联规则和对应的支持度和置信度。