自考题库
首页
所有科目
自考历年真题
考试分类
关于本站
游客
账号设置
退出登录
注册
登录
出自:国家开放大学《数据结构》
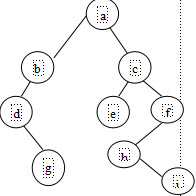
如图所示的二叉树,其先序遍历序列为()。
以下是中序遍历二叉树的递归算法的程序,完成程序中空格部分(树结构中左、右指针域分别为left和right,数据域data为字符型,BT指向根结点)。
在一个链队中,设f和r分别为队头和队尾指针,则插入s所指结点的操作为r->next=s;和()(结点的指针域为next)。
以下函数为链队列的入队操作,x为要入队的结点的数据域的值,front、rear分别是链队列的对头、队尾指针。
以下程序是后序遍历二叉树的递归算法的程序,完成程序中空格部分(树结构中左、右指针域分别为left和right,数据域为data,其数据类型为字符型,BT指向根结点)。
要在一个单向链表中p所指向的结点之后插入一个S所指向的新结点,若链表中结点的指针域为next,可执行()和p->next==s的操作。
()查找是一种最简单的查找方法。
在一棵度具有5层的满二叉树中结点总数为()。
A:31
B:32
C:16
D:33
已知一个图的所有顶点的度数之和为m,则m一定不可能是()。
A:4
B:8
C:12
D:9
在一个单向链表中p所指结点之后插入一个s所指向的结点时,应执行s->next=p->next;和()的操作。
排序过程中,每一趟从无序子表中将一个待排序的记录按其关键字的大小放置到已经排好序的子序列的适当位置,直到全部排好序为止,该排序算法是()。
A:直接插入排序
B:快速排序
C:冒泡排序
D:选择排序
对给定权值2,1,3,3,4,5构造两棵哈夫曼树,使两棵哈夫曼树有不同的高度,并分别求两棵树的带权路径长度。
在对一组记录(55,39,97,22,16,73,65,47,88)进行直接插入排序时,当把第7个记录65插入到有序表时,为寻找插入位置需比较()次。
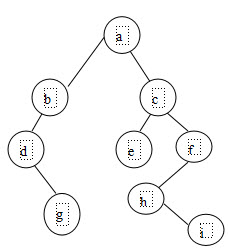
如图所示的二叉树,其后序遍历序列为()。
带头结点的单向链表的头指针为head,该链表为空的判定条件是()的值为真。
A:head==NULL
B:head->next==head
C:head->next==NULL
D:head==head->next
一个有序表{3,4,10,14,34,43,46,64,75,78,90,96,130}用折半查找法查找值为90的结点,经()次比较后查找成功。
链表所具备的特点是()。
A:可以随机访问任一结点
B:占用连续的存储空间
C:插人删除元素的操作不需要移动元素结点
D:可以通过下标对链表进行直接访问
一棵二叉树顺序编号为6的结点(树中各结点的编号与等深度的完全二叉中对应位置上结点的编号相同),若它存在右孩子,则右孩子的编号为()。
利用3、6、8、12这四个值作为叶子结点的权,生成一棵哈夫曼树,该树中所有叶子结点中的最长带权路径长度为()。
A:16
B:30
C:12
D:18
串函数StrCmp("b","cd")的值为()。
A:1
B:0
C:"bcd"
D:-1
一组记录的关键字序列为(47,80,57,39,41,46),利用堆排序(堆顶元素是最小元素)的方法建立的初始堆为()。
A:39,47,46,80,41,57
B:39,41,46,80,47,57
C:41,39,46,47,57,80
D:39,80,46,47,41,57
在解决计算机主机与打印机之间速度不匹配问题时通常设置一个打印数据缓冲区,主机将要输出的数据依次写入缓冲区中,而打印机则从缓冲区中取出数据打印,该缓冲区应该是一个()结构。
A:队列
B:先性表
C:数组
D:堆栈
一组记录的关键字序列为{45,40,65,43,35,95}写出利用快速排序的方法,以第一个记录为基准得到的一趟划分的结果(要求给出一趟划分中每次扫描和交换的结果)。
数据的()结构与所使用的计算机无关。
A:逻辑
B:物理
C:存储
D:逻辑与存储
已知序列{11,19,5,4,7,13,2,10}。
第1题,共2个问题
(简答题)试给出用归并排序法对该序列作升序排序时的每一趟的结果。
第2题,共2个问题
(简答题)对上述序列用堆排序的方法建立初始堆(要求小根堆,以二叉树描述建堆过程)。
栈和队列的操作特点分别是()和()。
已知某二叉树的先序遍历序列是aecdb,中序遍历序列是eadcb。给出上述二叉树的后序遍历序列。
在对一组记录(50,40,95,20,15,70,60,45,80)进行直接插入排序时,当把第7个记录60插入到有序表时,为寻找插入位置需要比较()次。
已知某二叉树的先序遍历结果是:A,B,D,G,C,E,H,L,I,K,M,F和J,它的中序遍历结果是:G,D,B,A,L,H,E,K,I,M,C,F和J,请画出这棵二叉树,并写出该二叉树后续遍历的结果。
串函数StrCmp(“abA”,”aba”)的值为()。
A:1
B:0
C:“abAaba”
D:-1
首页
<上一页
7
8
9
10
11
下一页>
尾页