自考题库
首页
所有科目
自考历年真题
考试分类
关于本站
游客
账号设置
退出登录
注册
登录
出自:数据挖掘工程师
什么是决策节点?
简述数据预处理方法和内容。
从应用的角度看,数据仓库的发展演变可以归纳为5个阶段:以报表为主、()、以预测模型为主、以运营导向为主和以实时数据仓库和自动决策为主。
在项目实施时,根据事实表的特点和拥护的查询需求,可以选用()、业务类型、区域和下属组织等多种数据分割类型。
简述数据分类的两步过程。
为什么要建立数据仓库?
数据集如下表所示:
(a)把每一个事务作为一个购物篮,计算项集{e},{b,d}和{b,d,e}的支持度。 (b)利用(a)中结果计算关联规则{b,d}→{e}和{e}→{b,d}的置信度。置信度是一个对称的度量吗? (c)把每一个用户购买的所有商品作为一个购物篮,计算项集{e},{b,d}和{b,d,e}的支持度。 (d)利用(b)中结果计算关联规则{b,d}→{e}和 {e}→{b,d}的置信度。置信度是一个对称的度量吗?
下面哪个
不属于
数据的属性类型:()。
A:标称
B:序数
C:区间
D:相异
业务元数据主要包含的内容是什么?
平均值函数avg()属于哪种类型的度量?()
A:分布的
B:代数的
C:整体的
D:混合的
数据归约的目的是()。
A:填补数据种的空缺值
B:集成多个数据源的数据
C:得到数据集的压缩表示
D:规范化数据
分别说明利用支持度、置信度和提升度评价关联规则的优缺点。
贝叶斯信念网络(BBN)有如下哪些特点,()。
A:构造网络费时费力
B:对模型的过分问题非常鲁棒
C:贝叶斯网络不适合处理不完整的数据
D:网络结构确定后,添加变量相当麻烦
如何用决策树进行分类?
聚类分析常作为一个独立的工具来获得()
简述抽样的定义及分类。
简述维度归约和特征变换。
数据变换的内容是什么?
考虑两队之间的足球比赛:队0和队1。假设65%的比赛队0胜出,剩余的比赛队1获胜。队0获胜的比赛中只有30%是在队1的主场,而队1取胜的比赛中75%是主场获胜。如果下一场比赛在队1的主场进行队1获胜的概率为()。
A:0.75
B:0.35
C:0.4678
D:0.5738
K均值是一种产生划分聚类的基于密度的聚类算法,簇的个数由算法自动地确定。
根据规则中所处理的值类型,关联规则可分为:()和()
数据挖掘应用和一些常见的数据统计分析系统的最主要区别在于()。
A:所涉及的算法的复杂性
B:所涉及的数据量
C:计算结果的表现形式
D:是否使用了人工智能技术
数据仓库在技术上的工作过程是()。
A:数据的抽取
B:存储和管理
C:数据的表现
D:数据仓库设计
考虑这么一种情况:一个对象碰巧与另一个对象相对接近,但属于不同的类,因为这两个对象一般不会共享许多近邻,所以应该选择()的相似度计算方法。
A:平方欧几里德距离
B:余弦距离
C:直接相似度
D:共享最近邻
简述分类模型的评价。
简述K-平均算法的输入、输出及聚类过程(流程)。
OLAP
抽取、转换、加载过程的目的是为决策支持应用提供一个()、权威数据源。因此,我们要求ETL过程产生的数据是详细的、历史的、规范的、可理解的、即时的和质量可控制的。
下面哪种
不属于
数据预处理的方法?()
A:变量代换
B:离散化
C:聚集
D:估计遗漏值
频繁项集
首页
<上一页
4
5
6
7
8
下一页>
尾页
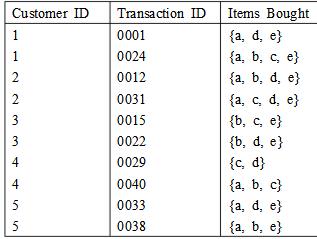 (a)把每一个事务作为一个购物篮,计算项集{e},{b,d}和{b,d,e}的支持度。 (b)利用(a)中结果计算关联规则{b,d}→{e}和{e}→{b,d}的置信度。置信度是一个对称的度量吗? (c)把每一个用户购买的所有商品作为一个购物篮,计算项集{e},{b,d}和{b,d,e}的支持度。 (d)利用(b)中结果计算关联规则{b,d}→{e}和 {e}→{b,d}的置信度。置信度是一个对称的度量吗?
(a)把每一个事务作为一个购物篮,计算项集{e},{b,d}和{b,d,e}的支持度。 (b)利用(a)中结果计算关联规则{b,d}→{e}和{e}→{b,d}的置信度。置信度是一个对称的度量吗? (c)把每一个用户购买的所有商品作为一个购物篮,计算项集{e},{b,d}和{b,d,e}的支持度。 (d)利用(b)中结果计算关联规则{b,d}→{e}和 {e}→{b,d}的置信度。置信度是一个对称的度量吗?