自考题库
首页
所有科目
自考历年真题
考试分类
关于本站
游客
账号设置
退出登录
注册
登录
出自:数据挖掘工程师
以下两种描述分别对应哪两种对分类算法的评价标准?() (1)警察抓小偷,描述警察抓的人中有多少个是小偷的标准。 (2)描述有多少比例的小偷给警察抓了的标准。
A:Precision,Recall
B:Recall,Precision
C:Precision,ROC
D:Recall,ROC
以下是哪一个聚类算法的算法流程()。 ①构造k-最近邻图。 ②使用多层图划分算法划分图。 ③repeat:合并关于相对互连性和相对接近性而言,最好地保持簇的自相似性的簇。 ④until:不再有可以合并的簇。
A:MST
B:OPOSSUM
C:Chameleon
D:Jarvis-Patrick(JP)
离散属性总是具有有限个值。
依据类信息可利用的程度,离群点挖掘可分为哪三种基本方法?
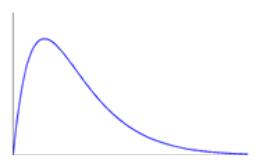
对于下图所示的正倾斜数据,中位数、平均值、众数三者之间的关系是()
A:中位数=平均值=众数;
B:中位数>平均值>众数;
C:平均值>中位数>众数;
D:众数>中位数>平均值
什么是数据仓库的3层数据结构?
请描述主成份分析(PCA)算法步骤
关于OLAP的特性,下面正确的是:()。 (1)快速性 (2)可分析性 (3)多维性 (4)信息性 (5)共享性
A:(1)(2)(3)
B:(2)(3)(4)
C:(1)(2)(3)(4)
D:(1)(2)(3)(4)(5)
粒度是对数据仓库中数据的综合程度高低的一个衡量。粒度越小,细节程度越高,综合程度越低,回答查询的种类()
数据挖掘的效果直接受到()的影响。
根据关联分析中所涉及的数据维,可以将关联规则分类为()。
A:布尔关联规则
B:单维关联规则
C:多维关联规则
D:多层关联规则
数据仓库
关于数据仓库的设计,四种不同的视图必须考虑,分别是:()、()、()、()
在现实世界的数据中,元组在某些属性上缺少值是常有的。描述处理该问题的各种方法有:()。
A:忽略元组
B:使用属性的平均值填充空缺值
C:使用一个全局常量填充空缺值
D:使用与给定元组属同一类的所有样本的平均值
E:使用最可能的值填充空缺值
在数据挖掘中,常用的聚类算法包括:()、()、()、基于网格的方法和基于模型的方法。
哪种OLAP操作可以让用户在更高的抽象层,更概化的审视数据?()
A:上卷
B:下钻
C:切块
D:转轴
什么是技术元数据?主要包含的内容是什么?
为什么要关注离群点?
通过数据挖掘过程所推倒出的关系和摘要经常被称为:()。
A:模型
B:模式
C:模范
D:模具
试述对于多个异种信息源的集成,为什么许多公司宁愿使用更新驱动的方法(update-driven),而不愿使用查询驱动(query-driven)的方法?
简述数据仓库ETL软件的主要功能和对产生数据的目标要求。
()这些数据特性都是对聚类分析具有很强影响的。
A:高维性
B:规模
C:稀疏性
D:噪声和离群点
评估分类模型的性能的方法有哪些?
一种常用的确定离群点的简单方法是()
下面属于维归约常用的线性代数技术的有()。
A:主成分分析
B:特征提取
C:奇异值分解
D:特征加权
E:离散化
在基本K均值算法里,当邻近度函数采用()的时候,合适的质心是簇中各点的中位数。
A:曼哈顿距离
B:平方欧几里德距离
C:余弦距离
D:Bregman散度
检测一元正态分布中的离群点,属于异常检测中的基于()的离群点检测。
A:统计方法
B:邻近度
C:密度
D:聚类技术
调和数据是存储在()数据仓库和操作型数据存储中的数据。
雪花型模式是对()维表的进一步层次化和规范化来消除冗余的数据。
建立一个模型,通过这个模型根据已知的变量值来预测其他某个变量值属于数据挖掘的哪一类任务?()
A:根据内容检索
B:建模描述
C:预测建模
D:寻找模式和规则
首页
<上一页
2
3
4
5
6
下一页>
尾页