自考题库
首页
所有科目
自考历年真题
考试分类
关于本站
游客
账号设置
退出登录
注册
登录
出自:国家开放大学《数据结构》
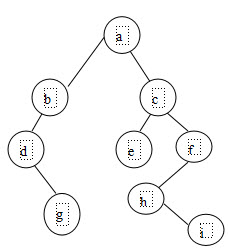
如图所示的二叉树,其先序遍历序列为()。
以下函数在a[0]到a[n-1]中,用折半查找算法查找关键字等于k的记录,查找成功返回该记录的下标,失败时返回-1,完成程序中的空格。
线性链表的逻辑关系是通过每个结点指针域中的指针来表示的。其逻辑顺序和物理存储顺序不再一致,而是一种()存储结构,又称为()。
通常可以把一本含有不同章节的书的目录结构抽象成()结构。
在一棵树中,每个结点的()或者说每个结点的()称为该结点的(),简称为孩子。
设有一个带头结点的链队列,队列中每个结点由一个数据域data和指针域next组成,front和rear分别为链队列的头指针和尾指针,要执行出队操作,用x保存出队元素的值,p为指向结点类型的指针,可执行如下操作:p=front->next;x=p->data;然后指行()。
A:front=p->next;
B:front->next=p;
C:front=p;
D:front->next=p->next;
结构中的数据元素存在多对多的关系称为()结构。
中序遍历二叉排序树可得到一个()。
在一棵度为3的树中,度为3的结点个数为2,度为2的结点个数为1,则度为0的结点个数为()。
A:5
B:4
C:7
D:6
以于说法正确的是()。
A:队列是后进先出
B:栈的特点是后进后出
C:栈的删除和插入操作都只能在栈顶进行
D:队列的删除和捶入操作都只能在队头进行
有一个有序表{2,3,9,13,33,42,45,63,74,77,82,95,110},用折半查找法查找值为82的结点,经()次比较后查找成功。
以下程序是后序遍历二叉树的递归算法的程序,完成程序中空格部分(树结构中,左、右指针域分别为left和right,数据域data为字符型,BT指向根结点)。
排序方法中,从未排序序列中挑选元素,并将其依次放入已排序序列(初始为空)的一端的方法,称为()排序。
A:插入
B:快速
C:选择
D:归并
哈希表是用来存放查找表中记录序列的表,每一个记录的存储位置是以该记录得到关键字为(),由相应哈希函数计算所得到的()。
设有一个10阶的对称矩阵A,采用压缩存储的方式,将其下三角部分以行序为主序存储到一维数组B中(数组下标从1开始),则矩阵中元素A8,5在一维数组B中的下标是()。
A:33
B:32
C:85
D:41
设有一个头指针为head的单向循环链表,p指向链表中的结点,若p->next=(),则p所指结点为尾结点。
一组记录的关键字序列为(46,79,56,38,40,84),利用快速排序,以第一个关键字为分割元素,经过一次划分后结果为()。
A:40,38,46,79,56,84
B:40,38,46,84,56,79
C:40,38,46,56,79,84
D:38,40,46,56,79,84
按某关键字对记录序列排序,()若在排序前和排序后仍保持它们的前后关系,则排序算法是稳定的,否则是不稳定的。
若让元素1,2,3依次进栈,则出栈顺序不可能为()。
A: 2,1,3
B: 3,1,2
C: 3,2,1
如图所示的二叉树,其中序遍历序列为()。
二叉树为二叉排序的充分必要条件是其任一结点的值均大于其左孩子的值、小于其右孩子的值。
冒泡排序是一种比较简单的()方法。
在堆排序和快速排序中,若原始记录接近正序和反序,则选用(),若原始记录无序,则最好选用()。
算法的时间复杂度与()有关。
A:所使用的计算机
B:数据结构
C:算法本身
D:计算机的操作系统
从长度为n的采用顺序存储结构的线性表中删除第i(1£i£n+1)个元素,需向前移动()个元素。
循环队列的最大存储空间为MaxSize=6,采用少用一个元素空间以有效地判断栈空或栈满,若队头指针front=4,当队尾指针rear=()时队满,队列中共有()个元素。
在一个查找表中,能够唯一地确定一个记录的关键字称为()。
设有一个单向循环链表,头指针为head,链表中结点的指针域为next,p指向尾结点的直接前驱结点,若要删除尾结点,得到一个新的单向循环链表,可执行操作()。
数据结构中,与所使用的计算机无关的是数据的()。
A:物理结构
B:逻辑结构
C:物理和存储结构
D:存储结构
针对线性表,在存储后如果最常用的操作是取第i个结点及其前驱,则采用()存储方式最节省时间。
A:单链表
B:双链表
C:单循环链表
D:顺序表
首页
<上一页
1
2
3
4
5
下一页>
尾页