自考题库
首页
所有科目
自考历年真题
考试分类
关于本站
游客
账号设置
退出登录
注册
登录
出自:国家开放大学《数据结构》
设一棵有n个结点采用链式存储的二叉树,则该树共有()个指针域为空。
A:2n
B:2n+1
C:2n+2
D:n+1
数组a经初始化chara[]=“English”;a[7]中存放的是()。
A:"h"
B:字符串的结束符
C:变量h
D:字符h
一棵哈夫曼树有12个叶子结点(终端结点),该树总共有()个结点。
A:22
B:21
C:23
D:24
已知一个图的边数为m.则该图的所有顶点的度数之和为()。
A:2m
B:m
C:2m+1
D:m/2
设线性表为(6,10,16,4),以下程序用说明结构变量的方法建立单向链表,并输出链表中各结点中的数据。
用折半查找法,对长度为12的有序的线性表进行查找,最坏情况下要进行()次元素间的比较。
A:4
B:3
C:5
D:6
一棵二叉树叶结点(终端结点)数为5,单分支结点数为2,该树共有()个结点。
一棵哈夫曼树有n个叶子结点(终端结点),该树总共有()个结点。
A:2n-2
B:2n-1
C:2n
D:2n+2
循环队列的队头指针为f,队尾指针为r,当()时表明队列为空。
设一棵完全二叉树,其最高层上最右边的叶结点的编号为偶数,该叶节点的双亲结点的编号为9,该完全二叉树一共有()个结点。
空串的长度是()。
向一个有127个元素的顺序表中插入一个新元素,并保持原来的顺序不变,平均要移动()个元素。
A:8
B:7
C:63
D:63.5
一棵二叉树总结点数为11,叶结点数为5,该树有()个双分支结点,()个单分支结点。
环队列的引入,目的是为了克服()。
一棵具有35个结点的完全二叉树,最后一层有()个结点。
A:4
B:6
C:16
D:8
按照二又树的递归定义,对二叉树遍历的常用算法有()、()、()三种。
向一个栈顶指针为h的链栈中插入一个s所指结点时,可执行s->next=h;和()操作。(结点的指针域为next)
哈夫曼树又称为(),它是n个带权叶子结点构成的所有二叉树中带权路径长度WPL()。
设顺序存储的线性长度为n,要在第i个元素之前插入一个新元素,按课本的算法当i=()时,移动元素次数为2。
A:n/2
B:n
C:n-1
D:1
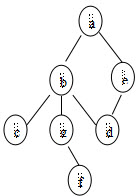
如图若从顶点a出发按深度优先搜索法进行遍历,则可能得到的顶点序列为()。
A:acfgedb
B:aedbgfc
C:acfebdg
D:aecbdgf
深度为k的二叉树最多有()个结点。
在一个单向链表中,要删除p所指结点,已知q指向p所指结点的前驱结点。则可以用操作()。
设有一个10阶的对称矩阵A,采用压缩存储方式将其下三角部分以行序为主序存储到一维数组b中。(矩阵A的第一个元素为al,l,数组b的下标从1开始),则矩阵元素a5,3对应一维数组b的数组元素是()。
A:b[18]
B:b[8]
C:b[13]
D:b[lO]
下列是用头插法建立带头结点的且有n个结点的单向链表的算法,请在空格内填上适当的语句。
给定数列{8,17,5,9,21,10,7,19,6},依次取序列中的数构造一棵二叉排序树。并对上述二叉树给出中序遍历得到的序列。
在一个栈顶指针为top的链栈中删除一个结点时,用x保存被删除的结点,应执行()。
A:x=top->data;top=top->next;
B:top=top->next;x=top;
C:x=top;top=top->next;
D:x=top->data;
“一棵二叉树若它的根结点的值大于左子树所有结点的值,小于右子树所有结点的值,则该树一定是二叉排序树”。设有查找表{7,16,4,8,20,9,6,18,5},依次取表中数据构造一棵二叉排序树.对上述二叉树给出后序遍历的结果。
设有一个长度为n的顺序表,要删除第i个元素移动元素的个数为()。
A:n-i
B:n-i-1
C:n-i+1
D:i
在对一组元素(64,48,106,33,25,82,70,55,93)进行直接插入排序时,当进行到要把第7个元素70插入到已经排好序的子表时,为找到插入位置,需进行()次元素间的比较(指由小到大排序)。
A:6
B:2
C:3
D:4
设已有m个元素有序,在未排好序的序列中挑选第m+1个元素,并且只经过一次元素的交换就使第m+1个元素排序到位,该方法是()。
A:折半排序
B:冒泡排序
C:归并排序
D:简单选择排序
首页
<上一页
1
2
3
4
5
下一页>
尾页