自考题库
首页
所有科目
自考历年真题
考试分类
关于本站
游客
账号设置
退出登录
注册
登录
出自:数据挖掘工程师
如果规则不满足置信度阈值,则形如的规则一定也不满足置信度阈值,其中是X的子集。
什么是基于像素的可视化技术?它有什么缺点?
关于OLAP和OLTP的说法,下列
不正确
的是()
A:OLAP事务量大,但事务内容比较简单且重复率高
B:OLAP的最终数据来源与OLTP不一样
C:OLTP面对的是决策人员和高层管理人员
D:OLTP以应用为核心,是应用驱动的
简述数据仓库的组成。
常见的聚类算法可以分为几类?
考虑如下的频繁3-项集:{1,2,3},{1,2,4},{1,2,5},{1,3,4},{1,3,5},{2,3,4},{2,3,5},{3,4,5}。 (a)根据Apriori算法的候选项集生成方法,写出利用频繁3-项集生成的所有候选4-项集。 (b)写出经过剪枝后的所有候选4-项集。
以下哪项关于决策树的说法是错误的?()
A:冗余属性不会对决策树的准确率造成不利的影响
B:子树可能在决策树中重复多次
C:决策树算法对于噪声的干扰非常敏感
D:寻找最佳决策树是NP完全问题
根据关联分析中所处理的值类型,可以将关联规则分类为()。
A:布尔关联规则和量化关联规则
B:单维关联规则和多维关联规则
C:单层关联规则和多层关联规则
D:简答关联规则和复杂关联规则
如果规则集R中不存在两条规则被同一条记录触发,则称规则集R中的规则为()。
A:无序规则
B:穷举规则
C:互斥规则
D:有序规则
以下哪个指标不是表示对象间的相似度和相异度?()
A:Euclidean距离
B:Manhattan距离
C:Eula距离
D:Minkowski距离
请简述几种典型的多维数据的OLAP操作
下列哪个不是专门用于可视化时间空间数据的技术:()。
A:等高线图
B:饼图
C:曲面图
D:矢量场图
可信度
什么是星型模式?它的特征是什么?
可视化技术对于分析的数据类型通常不是专用性的。
数据挖掘定义是什么?
什么是用户信息需求表(信息包图法)?它为什么适用于数据仓库的概念模型的设计?
下表所示的相依表汇总了超级市场的事务数据。其中hot dogs指包含热狗的事务,
指不包含热狗的事务。hamburgers指包含汉堡的事务,
指不包含汉堡的事务。
假设挖掘出的关联规则是“hot dogs=>hamburgers”。给定最小支持度阈值25%和最小置信度阈值50%,这个关联规则是强规则吗? 计算关联规则“hot dogs=>hamburgers”的提升度,能够说明什么问题?购买热狗和购买汉堡是独立的吗?如果不是,两者间存在哪种相关关系?
分类器设计阶段包含三个过程:划分数据集、分类器构造和()
分类知识的发现方法主要有哪些?分类过程通常包括哪两个步骤?
数据清理的目的是什么?
一个好的聚类分析方法会产生高质量的聚类,具有两个特征:()和()
何谓相异度矩阵?它有什么特点?
ID3算法主要存在的缺点是什么?
利用先验原理可以帮助减少频繁项集产生时需要探查的候选项个数。
下列哪些是数据变换可能涉及的内容?()
A:数据压缩
B:数据概化
C:维归约
D:规范化
假定用于分析的数据包含属性age。数据元组中age的值如下(按递增序):13,15,16,16,19,20,20,21,22,22,25,25,25,30,33,33,35,35,36,40,45,46,52,70,问题:使用按箱平均值平滑方法对上述数据进行平滑,箱的深度为3。第二个箱子值为:()。
A:18.3
B:22.6
C:26.8
D:27.9
什么是数据清洗?
数据仓库的多维数据模型可以有三种不同的形式,分别是:()、()和()
为什么在进行联机分析处理(OLAP)时,我们需要一个独立的数据仓库,而不是直接在日常操作的数据库上进行。
首页
<上一页
10
11
12
13
14
下一页>
尾页
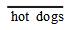 指不包含热狗的事务。hamburgers指包含汉堡的事务,
指不包含热狗的事务。hamburgers指包含汉堡的事务,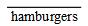 指不包含汉堡的事务。
指不包含汉堡的事务。 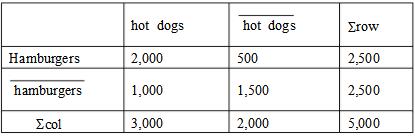 假设挖掘出的关联规则是“hot dogs=>hamburgers”。给定最小支持度阈值25%和最小置信度阈值50%,这个关联规则是强规则吗? 计算关联规则“hot dogs=>hamburgers”的提升度,能够说明什么问题?购买热狗和购买汉堡是独立的吗?如果不是,两者间存在哪种相关关系?
假设挖掘出的关联规则是“hot dogs=>hamburgers”。给定最小支持度阈值25%和最小置信度阈值50%,这个关联规则是强规则吗? 计算关联规则“hot dogs=>hamburgers”的提升度,能够说明什么问题?购买热狗和购买汉堡是独立的吗?如果不是,两者间存在哪种相关关系?