自考题库
首页
所有科目
自考历年真题
考试分类
关于本站
游客
账号设置
退出登录
注册
登录
出自:数据挖掘工程师
下面关于Jarvis-Patrick(JP)聚类算法的说法
不正确
的是()。
A:JP聚类擅长处理噪声和离群点,并且能够处理不同大小、形状和密度的簇
B:JP算法对高维数据效果良好,尤其擅长发现强相关对象的紧致簇
C:JP聚类是基于SNN相似度的概念
D:JP聚类的基本时间复杂度为O(m)
下面哪些问题是我们进行数据预处理的原因?()
A:数据中的空缺值
B:噪声数据
C:数据中的不一致性
D:数据中的概念分层
下列几种数据挖掘功能中,()被广泛的应用于股票价格走势分析。
A:关联分析
B:分类和预测
C:聚类分析
D:演变分析
确定了数据仓库的粒度模型以后,为提高数据仓库的使用性能,还需要根据拥护需求设计()
数据仓库后端工具和程序包括哪些?
朴素贝叶斯分类是基于()假设。
孤立点挖掘适用于下列哪种场合?()
A:目标市场分析
B:购物篮分析
C:模式识别
D:信用卡欺诈检测
聚类分析可以看作是一种非监督的分类。
数据挖掘的主要任务是从数据中发现潜在的规则,从而能更好的完成描述数据、预测数据等任务。
遗传算法
考虑下表所示二元分类问题的数据集。
(1)计算按照属性A和B划分时的信息增益。决策树归纳算法将会选择哪个属性? (2)计算按照属性A和B划分时Gini系数。决策树归纳算法将会选择哪个属性?
分类方法的常用评估度量都有哪些?
OLAP技术侧重于把数据库中的数据进行分析、转换成辅助决策信息,是继数据库技术发展之后迅猛发展起来的一种新技术。
一个典型的数据仓库系统由什么组成?
根据顾客的收入和职业情况,预测他们在计算机设备上的花费,所使用的相应数据挖掘功能是()。
A:关联分析
B:分类和预测
C:演变分析
D:概念描述
数据的噪声是指()。
A:孤立点
B:空缺值
C:测量变量中的随即错误或偏差
D:数据变换引起的错误
计算一个单位的平均工资,使用哪个中心趋势度量将得到最合理的结果?()
A:算术平均值
B:截尾均值
C:中位数
D:众数
从点作为个体簇开始,每一步合并两个最接近的簇,这是一种分裂的层次聚类方法。
下面
不属于
创建新属性的相关方法的是:()。
A:特征提取
B:特征修改
C:映射数据到新的空间
D:特征构造
何谓数据规范化?规范化的方法有哪些?写出对应的变换公式。
如果叶贝斯网络的各个结点都没有任何证据,从历史数据中如何用两种不同的方法得到各个结点的发生概率?
孤立点
按照事实表中度量的可加性情况,可以把事实表对应的事实分为4种类型:()、快照事实、线性项目事实和事件事实。
特征搜索过程中不可缺少的环节就是()。
维度表一般又主键、分类层次和描述属性组成。对于主键可以选择两种方式:一种是采用自然键,另一种是采用()
简述数据仓库4种体系结构的异同点以其适用性。
数据概化是指:()
关于OLAP和OLTP的区别描述,
不正确
的是()
A:OLAP主要是关于如何理解聚集的大量不同的数据.它与OTAP应用程序不同
B:与OLAP应用程序不同,OLTP应用程序包含大量相对简单的事务
C:OLAP的特点在于事务量大,但事务内容比较简单且重复率高
D:OLAP是以数据仓库为基础的,但其最终数据来源与OLTP一样均来自底层的数据库系统,两者面对的用户是相同的
支持度
下列关于分类和聚类哪个描述是正确的?()
A:分类和聚类都是有指导的学习
B:分类和聚类都是无指导的学习
C:分类是有指导的学习,聚类是无指导的学习
D:分类是无指导的学习,聚类是有指导的学习
首页
<上一页
9
10
11
12
13
下一页>
尾页
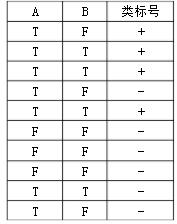 (1)计算按照属性A和B划分时的信息增益。决策树归纳算法将会选择哪个属性? (2)计算按照属性A和B划分时Gini系数。决策树归纳算法将会选择哪个属性?
(1)计算按照属性A和B划分时的信息增益。决策树归纳算法将会选择哪个属性? (2)计算按照属性A和B划分时Gini系数。决策树归纳算法将会选择哪个属性?